
MBZUAI launches comprehensive multimodal Arabic AI benchmark
CAMEL-Bench Arabic LMM benchmark spans eight diverse and challenging domains

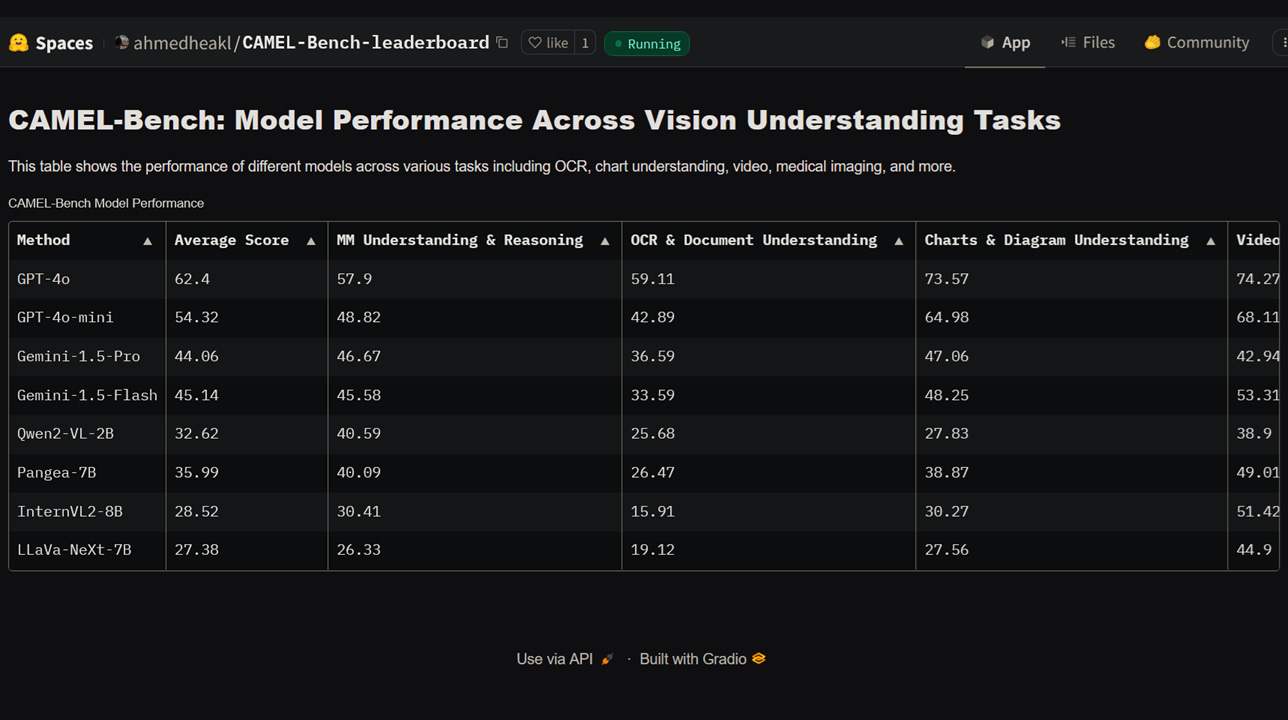
#UAE #evaluation - A research team led by Mohamed bin Zayed University for Artificial Intelligence (MBZUAI) has launched CAMEL-Bench, the most comprehensive benchmark for Arabic large multimodal models (LMMs), hosted on science platform and open-source AI community Hugging Face. The benchmark evaluates the performance of LMMs across diverse tasks like OCR, medical imaging, and remote sensing. CAMEL-Bench includes over 29k questions across 8 diverse domains and 38 sub-domains, curated by native Arabic speakers, and reveals critical performance gaps in popular models, with top-performing closed-source model GPT-4 reaching only 62%.
SO WHAT? - Accelerated by advances in technology and the hype surrounding the launch of OpenAI’s ChatGPT, the latest wave of multimodal models have inspired public imagination. Over the past year we’ve seen multimodal functions being integrated into popular models such as ChatGPT and Google’s Gemini. However, as with many advances in computing, multimodal models developed by Western companies are most proficient in the English language. The slower development of comprehensive Arabic LLMs has also meant that the development of Arabic-centric multimodal AI modals (LMMs) has lagged. Although the new leaderboard currently only ranks international English models, CAMEL-Bench could soon be used to evaluate new Arabic-centric LMMs developed in the Arab world, as researchers begin to integrate different modalities into Arabic language models.
Here are some key details about CAMEL-Bench:
A new leaderboard for a proposed benchmark for evaluating large multi-modal models (LMMs) called CAMEL-Bench, was pushed live on open-source AI community community Hugging Face this week. The comprehensive Arabic language LMM benchmark is part of the ORYX Library for Large Vision-Language Models curated by Mohammed bin Zayed University of Artificial Intelligence (MBZUAI).
CAMEL-Bench was developed by a team of researchers led by MBZUAI and including researchers from Aalto University (Finland), Linköping University (Sweden), and the Australian National University.
CAMEL-Bench covers eight diverse domains in the Arabic language including multimodal understanding and reasoning; OCR and document understanding; chart and diagram understanding; video understanding; cultural-specific understanding; medical imaging understanding; agricultural image understanding;, and remote sensing understanding.
The comprehensive benchmark includes 38 sub-domains with 29,036 questions specifically designed for Arabic language models, covering diverse tasks like video understanding and chart interpretation.
All questions have been carefully curated and verified by native Arabic speakers to ensure the benchmark’s cultural and linguistic relevance.
CAMEL-Bench evaluates both open and closed-source models, including popular options like GPT-4, Gemini, Qwen2, and InternVL2, comparing performance on a variety of visual and text-based tasks.
OpenAI’s closed-source model GPT-4o ranks first among global models, achieving a score of 62%, highlighting areas for significant improvement in Arabic LMM capabilities.
LINKS
CAMEL-Bench Leaderboard (Hugging Face)
CAMEL-Bench resource page (Github)
CAMEL-Bench research paper (arXiv, PDF)
CAMEL-Bench data set (Hugging Face)
ORXY Library (Github)
Read more about Arabic language evaluation models:
Arabic LLM index launched at GAIN (Middle East AI News)
Hugging Face introduces Open Arabic LLM Leaderboard (Middle East AI News)