
Hugging Face, Inception & MBZUAI launch new Arabic LLM leaderboard
New holistic & dynamic benchmark sets new standard in LLM evaluation

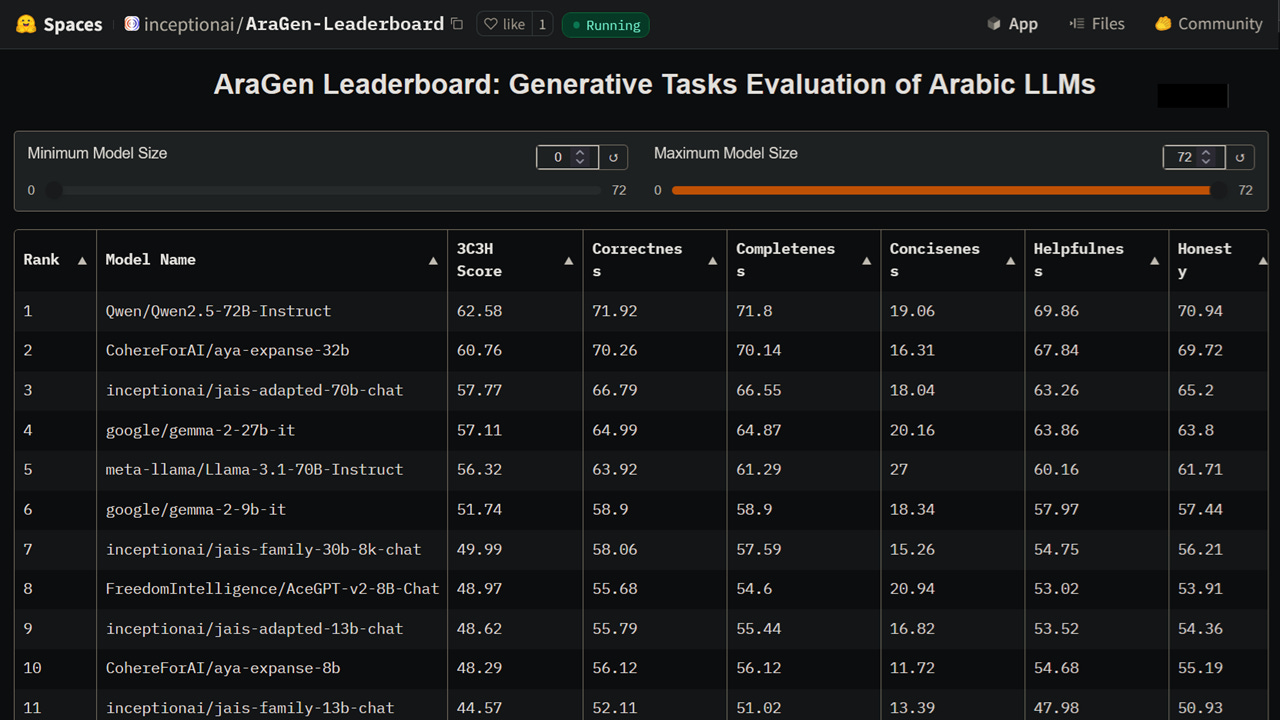
#UAE #evaluation - In the fast-evolving landscape of large language models (LLMs), evaluating their performance comprehensively remains a significant challenge, especially for low-resource languages. To address this, G42’s applied research arm Inception, in collaboration with Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and Hugging Face, have announced AraGen, a generative tasks benchmark and leaderboard for Arabic LLMs.
AraGen introduces the 3C3H Measure (a potentially revolutionary new evaluation measure for NLG, or natural language generation); the AraGen Benchmark (a meticulously constructed evaluation dataset for Arabic LLMs); and AraGen Leaderboard’s new dynamic benchmarking system. This combination of these new tools promises to create more robust, transparent, and reproducible assessments for Arabic LLMs: and potentially, other languages in the future.
SO WHAT? - The development of Arabic-centric large language models and models for other under-resourced languages is complex, time-consuming and nuanced. Arabic LLM developers use ‘all the tricks in the book’ to improve and enhance the qualify and performance of models, but each in a different way. Subsequently, measuring the quality and performance of all these different factors provides a challenge for LLM measurement and evaluation. The challenge is not only providing the ability to compare models using a variety of measures, but also that the final evaluation output is fair to the models, developers and ecosystem. The AraGen Benchmark promises to move Arabic LLM evaluation a leap forward, providing a new level of evaluation for usability, a key area often overlooked in existing frameworks.
Here are some details regarding the AraGen leaderboard and its components:
Abu Dhabi-based Inception, in collaboration with Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and Hugging Face, have announced AraGen, a generative tasks benchmark and leaderboard for Arabic-centric large language models (LLMs).
This leaderboard introduces generative tasks evaluation for Arabic LLMs powered by Inception’s new 3C3H evaluation framework, delivering a transparent, robust, and holistic evaluation system that balances factual accuracy and usability assessment for a production ready setting.
Researchers on this project are Ali El Filali (Inception); Neha Sengupta (Inception); Arwa Abouelseoud (Inception); Preslav Nakov (MBZUAI); and Clémentine Fourrier (Hugging Face).
The new 3C3H Measure provides a comprehensive framework evaluating six dimensions: Correctness, Completeness, Conciseness, Helpfulness, Honesty, and Harmlessness.
The AraGen Benchmark brings a meticulously constructed evaluation dataset for Arabic LLM evaluation, combining multi-turn and single-turn scenarios, which tests the model capability across multiple domains and tasks.
The benchmark uses a carefully designed dataset of 279 Arabic-language questions testing core capabilities like question answering, reasoning, orthographic analysis, and safety.
AraGen Leaderboard brings a dynamic evaluation framework, which includes three-month blind testing cycles for unbiased assessments with ever-evolving dataset. The evaluation datasets and the evaluation code remain private before being publicly released at the end of the cycle, and replaced by a new private benchmark.
By ensuring evaluation data remains private for three months, the AraGen Leaderboard prevents data leakage and ensures unbiased results.
The AraGen Leaderboard and AraGen Benchmark aim to enhance LLM benchmarking in Arabic, addressing the lack of dedicated resources for the language.
The developers hope that the AraGen Leaderboard to serve as a first-of-its-kind application of a scalable, language-agnostic framework for a nuanced and fair model assessment, representing an important effort in understanding LLM performance across diverse linguistic contexts and setting a new standard for comprehensive model benchmarking.
Although the theory has been articulated by the researchers in a blog post, the open-source code is expected to be made available in March 2025.
ZOOM OUT - Arabic LLMs are a continually evolving space due to the inherent challenges of working with the language, the limited data sets available and the nuances of numerous Arabic dialects. Therefore we can expect the evaluation of Arabic models to evolve continually also - and perhaps at a new, faster rate.
In May of this year, the community-driven Arabic AI Initiative (2A2I), in collaboration with Technology Innovation Institute (TII) and Hugging Face, went live with the Open Arabic LLM Leaderboard (OALL). In September, King Salman Global Academy for Arabic Language (KSGAAL) and Saudi Data and Artificial Intelligence Authority (SDAIA) launched the Balsam Index, an Arabic language index to evaluate and benchmark AI models. This was followed by research team led by Mohamed bin Zayed University for Artificial Intelligence (MBZUAI) delivering CAMEL-Bench in October, the most comprehensive benchmark for Arabic large multimodal models.
The AraGen Leaderboard and Benchmark represents another step forward, but also another slightly different set of benefits to its predecessors. Meanwhile, the new 3C3H evaluation measure could inspire other researchers to develop their own evaluation frameworks in the Arabic language and beyond.
LINKS
AraGen Leaderboard (Hugging Face)
AraGen Leaderboard 3C3H (Hugging Face)
Read more about LLM leaderboard and evaluation projects:
Comprehensive multimodal Arabic AI benchmark (Middle East AI News)
New telecom LLMs leaderboard project (Middle East AI News)
M42 delivers framework for evaluating clinical LLMs (Middle East AI News)
Arabic LLM index launched at GAIN (Middle East AI News)
New Hugging Face Open Arabic LLM Leaderboard (Middle East AI News)