
Saudi AI firm launches community-driven Arabic TTS leaderboard
Navid AI puts Arabic speakers in charge of rating AI voice models

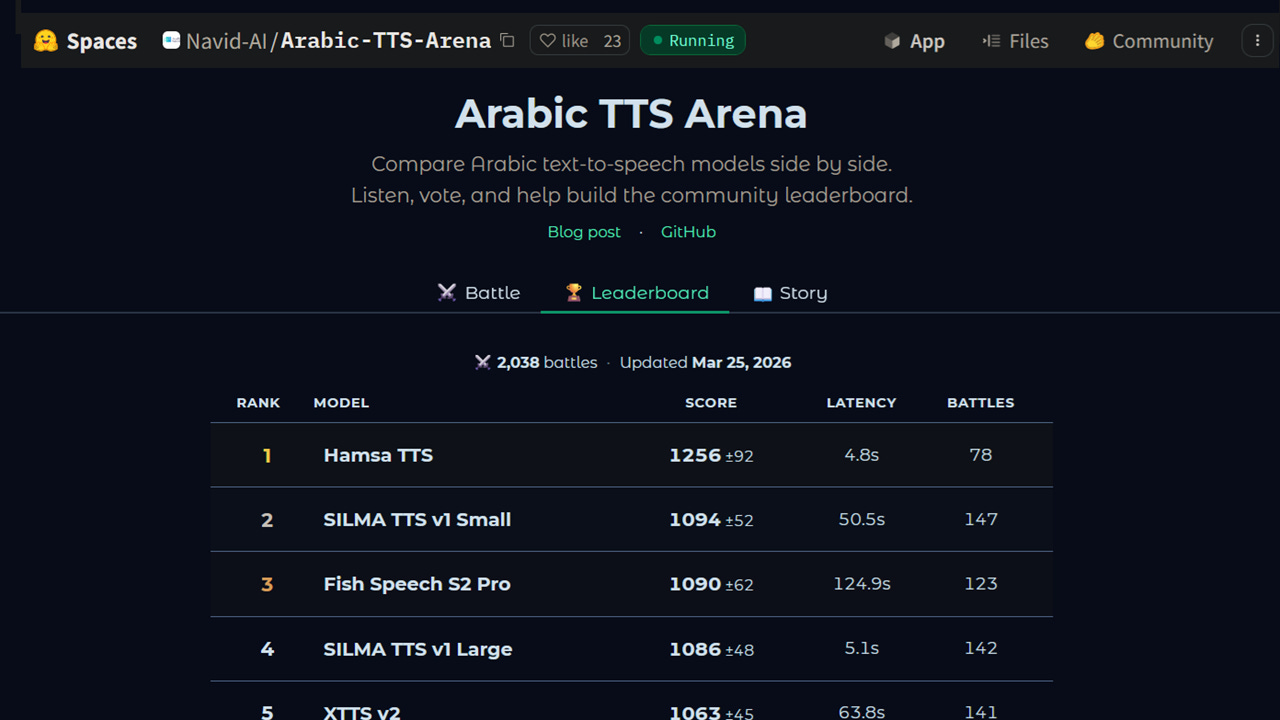
#SaudiArabia #TTS – Riyadh-based AI company Navid, the Generative AI arm of Watad, has launched the Arabic TTS Arena, an open, community-driven leaderboard for Arabic text-to-speech models. The platform lets Arabic speakers listen to two anonymous AI voice models reading the same text, vote for whichever sounds more natural, and collectively build a rankings table based on human preference rather than technical metrics. Currently hosting 15 models spanning open-source and commercial systems, the arena uses the Bradley-Terry rating model, the same mathematical framework that ranks chess grandmasters and powers the widely used LMArena large language model leaderboard. The model converts individual votes into ranked scores.
SO WHAT? – Arabic is spoken by over 400 million people across more than 20 countries. Despite the huge potential for use in customer service systems, reliable Arabic language text-to-speech is a relatively new thing. Meanwhile, text-to-speech evaluation has historically been driven by lab benchmarks and loss functions rather than the ears of native speakers. The Arabic TTS Arena changes the evaluation model entirely, putting human preference at the centre of how AI voice quality is measured. For a language with extraordinary dialectal diversity, this evaluation model could prove to be especially valuable. For synthetic speech, a benchmark that reflects what sounds people actually prefer to hear could be fundamentally more useful than one that reflects what an algorithm thinks sounds correct.
Here are some key points about the Arabic TTS leaderboard:
Riyadh-based AI company Navid, the Generative AI arm of Watad, has launched the Arabic TTS Arena leaderboard for Arabic text-to-speech models.
Arabic TTS Arena is an open platform hosted on Hugging Face, spanning both open-source and API-based commercial systems. The leaderboard currently ranking 15 Arabic TTS models including:
The platform uses the Bradley-Terry model, a maximum-likelihood statistical framework also used by LMArena (now Arena AI), the leading large language model leaderboard. The model converts pairwise human votes into ranked scores. Ratings are centred at 1000, with confidence intervals computed across 200 rounds of bootstrap resampling to ensure statistical reliability.
Model identities are hidden from voters until after they cast their vote, ensuring that brand recognition or prior reputation cannot influence judgements. Every vote reflects a pure listening preference rather than a preconceived opinion about a particular system.
Adding a new model to the arena requires only the implementation of a single Python class, with the platform discovering it automatically. Each model runs in its own containerised environment, and a daily automated process recomputes ratings and updates the leaderboard as new votes accumulate.
Navid’s analysis of existing Arabic TTS models produced what the research team calls the TTS Triangle, the argument that any complete text-to-speech system must address three dimensions simultaneously: what is being said, who is saying it, and how it is delivered. Most current Arabic models, they argue, address only one or two of these dimensions adequately.
On voice identity, the team argues that reducing Arabic’s extraordinary dialectal diversity to country-level labels (e.g. Egyptian, Saudi or Moroccan) is a fundamentally flawed approach. Arabic dialects vary dramatically within single countries and even cities, and the team advocates for systems built around specific reference speaker identities rather than broad geographic categories.
On delivery style, the team argues that emotion tags embedded in text (markers such as [laugh] or [sad]) fail to capture how human speech actually works, where emotion permeates an entire utterance rather than appearing as discrete events. They advocate instead for natural language delivery instructions, the same way a director guides a voice actor.
Navid draws a parallel with OpenAI’s TTS API, which already separates voice identity, textual content and delivery instructions into three distinct parameters, arguing this architecture is the right model for Arabic TTS. In fact the application of this model is arguably more important for Arabic than any other language given its dialectal and expressive breadth.
ZOOM OUT – The Watad group is no stranger to Arabic language AI development. Watad launched the Mulhem LLM in March 2024, described at the time as the first Saudi Arabia domain-specific large language model trained exclusively on Saudi data sets. The bilingual Arabic and English model was developed and trained entirely in the Kingdom on 90 billion Arabic and 90 billion English data tokens, using the company’s own curated data sets prioritising Saudi context. The seven billion parameter model was trained on more than 70,000 Saudi-specific question and answer data points and over 500,000 Arabic single and multi-turn conversational data sets. At launch, Watad reported that Mulhem outperformed comparable Arabic language models of the same size.
[Written and edited with the assistance of AI]
Read more about Arabic AI voice:
Velents raises $1.5 million for Arabic AI employee platform (Middle East AI News)
Egyptian AI startup Nanovate raises $2M Pre-Seed funding (Middle East AI News)
HUMAIN reveals Arabic TTS benchmark (Middle East AI News)
Arabic speech pioneer secures $12.5m Series A funding (Middle East AI News)
Jumia Egypt launches Arabic voice ecommerce (Middle East AI News)