
Stanford CRFM collabs with Arabic AI for HELM Arabic leaderboard
Arabic.AI’s flagship Arabic.AI LLM-X model now ranked top in new leaderboard

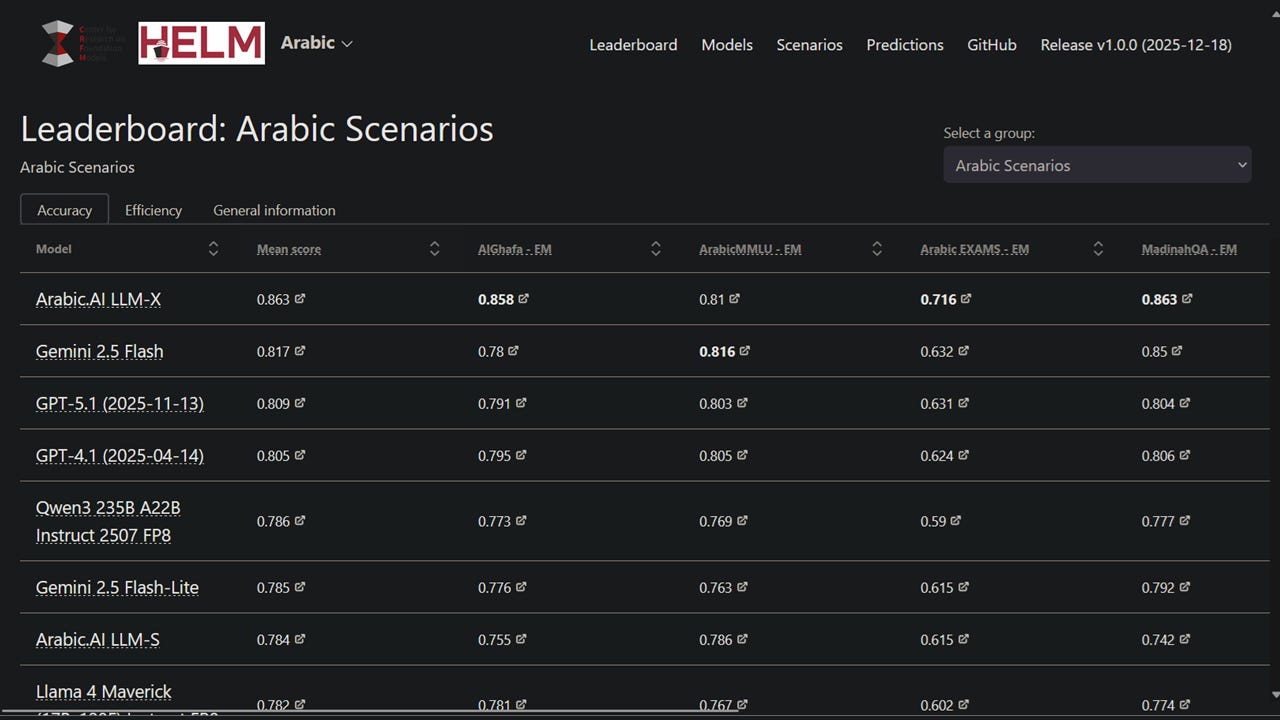
#UAE #LLMs – California-based Stanford University’s Center for Research on Foundation Models (Stanford CRFM), in collaboration with enterprise AI technology provider Arabic AI, has built HELM Arabic, a leaderboard for transparent and reproducible evaluation of large language models (LLMs) on Arabic language benchmarks. The project extends Stanford’s HELM framework, an open-source platform providing transparent and reproducible benchmarks for assessing foundation model capabilities and risks, into Arabic language evaluation. Arabic.AI’s flagship Arabic.AI LLM-X model (aka Pronoia) currently scores highest across seven benchmarks including AlGhafa, EXAMS, MadinahQA, AraTrust, ALRAGE and Translated MMLU.
SO WHAT? – The new benchmark is one of a number of initiatives aiming to close the gap in AI evaluation infrastructure for Arabic LLMs. Despite being a language spoken by over 400 million people, Arabic remains underserved by AI models and rigorous model assessment frameworks still lag behind English. By providing transparent, reproducible evaluation methodology comparable to frameworks used for English and other major languages, HELM Arabic enables objective comparison of model performance. Significantly, the leaderboard aims to evaluate both open-weight and commercial models.
Here are some key points about the new leaderboard:
Stanford University’s Center for Research on Foundation Models (Stanford CRFM), in collaboration with Middle East-based enterprise AI technology provider Arabic AI, has built HELM Arabic, a leaderboard for transparent and reproducible evaluation of large language models (LLMs) on Arabic language benchmarks.
The new Arabic LLM leaderboard ranks Arabic.AI LLM-X (also known as Pronoia) top, with the highest mean score across benchmarks and highest scores for AlGhafa, EXAMS, MadinahQA, AraTrust, ALRAGE and Translated MMLU, whilst open-weights multilingual model Qwen3 235B was best performing open-weights model with 0.786 mean score. Arabic.AI LLM-X is currently the only non-open model on the leaderboard that was trained specifically for Arabic.
Open-weights models trained or fine-tuned specifically for Arabic language, such as AceGPT-v2, ALLaM, JAIS and SILMA model families, underperformed compared to other groups. However, the Arabic-centric models benchmarked were all over a year old, with most recent models released in October 2024. For example, the Jais models currently benchmarked in HELM Arabic are 2024 releases, not from the latest Jais 2 model family released in December 2025.
The project extends Stanford’s HELM framework, an open-source platform providing transparent and reproducible benchmarks for foundation model assessment, into Arabic language evaluation with seven established Arabic-language evaluation tasks widely used in research community.
HELM Arabic includes seven benchmarks: AlGhafa multiple choice evaluation, ArabicMMLU native question answering from school exams, Arabic EXAMS high school questions, MadinahQA Arabic language and grammar testing, AraTrust Arab-region-specific safety evaluation, ALRAGE passage-based question answering, and ArbMMLU-HT human-translated MMLU.
The evaluation methodology used Arabic letters for multiple choice options, zero-shot prompting for instruction-tuned models, random sampling of 1,000 instances per subset to reduce imbalances, and disabled thinking modes on applicable models.
Open-weights multilingual models performed well relative to closed-weights multilingual models, with four open-weights models ranking in the top 10 positions: Qwen3 235B, Llama 4 Maverick, Qwen3-Next 80B and DeepSeek v3.1.
The leaderboard provides full transparency into all large language model requests and responses with reproducible results using the HELM open-source framework, serving as a resource for the Arabic natural language processing community.
ZOOM OUT – Arabic AI models have historically lacked dedicated evaluation benchmarks compared to English and Chinese language models, though recent developments have expanded assessment capabilities significantly. Abu Dhabi’s AI ecosystem has been at the forefront of the effort to expand and enhance the tools and benchmarks available for evaluating Arabic AI models. For example, Technology Innovation Institute released 3LM in August 2025, a comprehensive benchmark evaluating Arabic large language models on STEM reasoning and code generation. Earlier last year, Inception and Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) launched the Arabic Leaderboards Space on Hugging Face, introducing AraGen for evaluating generative models and Arabic Instruction Following for measuring command response.
[Written and edited with the assistance of AI]
LINKS
HELM Arabic Leaderboard (Stanford CRFM)
HELM Arabic Homepage (Stanford CRFM)
HELM Arabic blogpost (Stanford CRFM)
Read more about Arabic benchmarks:
TII releases new Arabic STEM AI benchmark (Middle East AI News)
Inception & MBZUAI share Arabic AI Leaderboards Space (Middle East AI News)
HF, Inception & MBZUAI launch Arabic leaderboard (Middle East AI News)
MBZUAI launches multimodal Arabic AI benchmark (Middle East AI News)