
Stanford, Arabic.AI launch Arabic Enterprise AI benchmark
New Arabic AI leaderboard tests models on finance and legal tasks

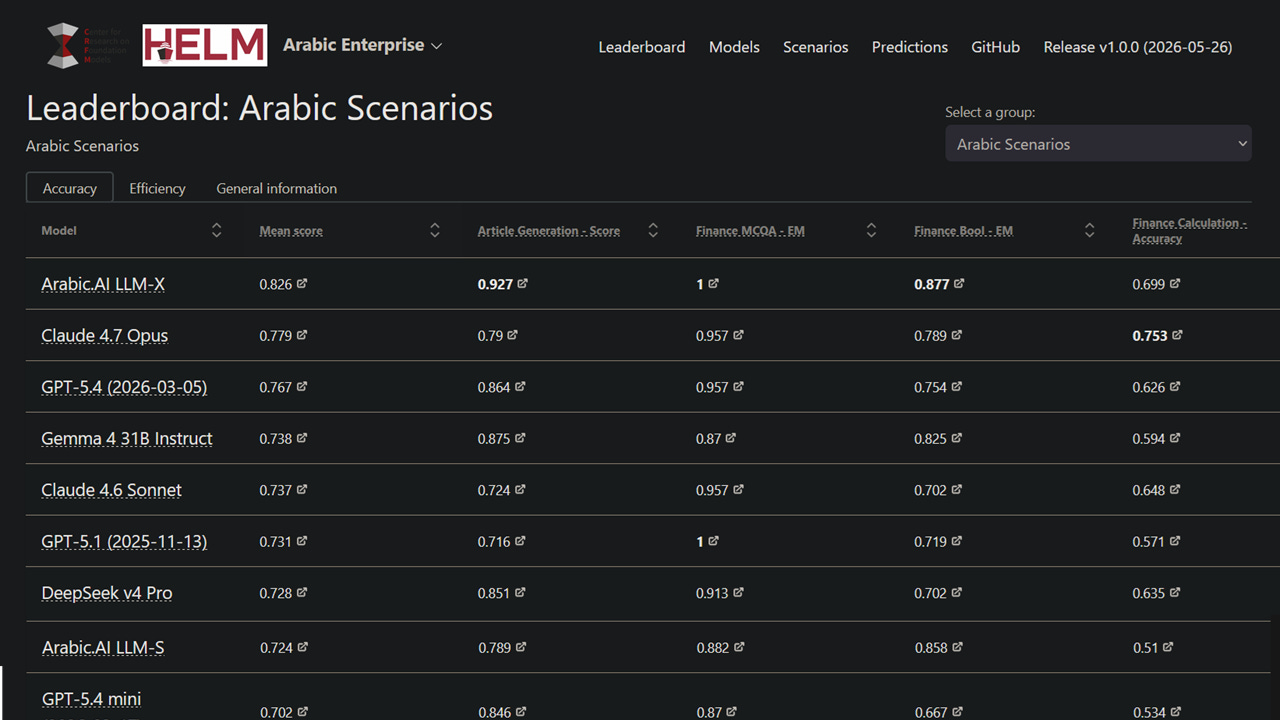
#UAE #ArabicAI – California-based Stanford University’s Center for Research on Foundation Models (Stanford CRFM), in collaboration with enterprise AI technology provider Arabic AI, has launched HELM Arabic Enterprise, the first structured benchmark designed to evaluate large language models (LLMs) on Arabic-language enterprise tasks. Built on Stanford’s globally recognised HELM evaluation framework, the leaderboard tests models across six tasks spanning corporate content generation, financial reasoning and UAE legal question answering, giving organisations a transparent, reproducible tool for comparing Arabic AI model performance in professional and regulated environments.
SO WHAT? – Until now, organisations deploying Arabic AI in enterprise settings have had no rigorous, shared benchmark to assess whether a model is actually fit for purpose in finance, legal or corporate communications workflows. General Arabic language performance is often not the same as Arabic enterprise performance and this leaderboard makes enterprise metrics measurable for the first time. The new HELM Arabic Enterprise aims to provide a baseline for organisation in the Arab world evaluating Arabic LLMs for business use.
KEY POINTS:
Stanford University’s Center for Research on Foundation Models (Stanford CRFM), in collaboration with Arabic AI, has launched HELM Arabic Enterprise, the first structured benchmark designed to evaluate large language models on Arabic-language enterprise tasks.
HELM Arabic Enterprise evaluates models across six enterprise-focused tasks: article generation, financial multiple choice question answering, financial boolean verification, financial calculation, and both open-book and closed-book UAE legal question answering. Each task is scored on a scale of 0 to 1, with results macro-averaged across all six.
Arabic.AI’s own LLM-X model topped the leaderboard with a mean score of 0.826, the highest of all models evaluated. It also achieved the highest scores in article generation (0.927), financial multiple choice (1.0), financial boolean verification (0.877), and closed-book legal question answering (0.495).
The leaderboard so far evaluates more than 20 models across three categories: closed-weights multilingual models including Claude 4, GPT-5.1, Gemini 2.5 and Command A; open-weights multilingual models including DeepSeek v4, Llama 4 and Qwen3.5. The benchmark also evaluates Arabic-specific models including ALLaM, JAIS and AceGPT-v2, but as with its predecessor HELM Arabic, the other Arabic models evaluated are not the latest releases and well over a year old.
The other Arabic-specific models were outperformed by general multilingual models across the board, but as the benchmark authors note this is likely due to the age of the models tested.
Legal question answering revealed a sharp performance gap between open-book and closed-book settings. The highest open-book score was 0.99, while the highest closed-book score was just 0.495 — indicating that most models lack sufficient embedded knowledge of UAE law to answer legal questions without being provided the relevant statute.
Financial calculation proved the hardest quantitative task, with the highest score reaching only 0.753. The benchmark authors attribute this to the difficulty of performing multi-step arithmetic reliably in Arabic without access to calculation tools..
Hallucination in Arabic content generation remains a widespread problem. Although some models scored well on article generation, many introduced unsupported facts into their output. The benchmark’s three-axis evaluation, across faithfulness, completeness and style adherence, is designed to separate models that are factually precise from those that are fluent but unreliable.
Full transparency and reproducibility are core to the leaderboard’s design. All prompts, model responses, metrics and scores are publicly available for inspection, and results can be independently reproduced using the open-source HELM framework. These allow organisations to use them to audit model behaviour rather than rely on headline scores alone.
ZOOM OUT – The HELM Arabic Enterprise leaderboard builds directly on an ongoing collaboration between Stanford CRFM and Arabic AI. In January of this year, the collaboration announced its the first leaderboard extending Stanford's HELM framework into Arabic language evaluation across seven established benchmarks, including AlGhafa, AraTrust, ALRAGE and Translated MMLU. The HELM Arabic leaderboard focused on general Arabic language capabilities, with Arabic.AI's LLM-X topping the rankings and open-weights multilingual models — particularly Qwen3 235B — performing strongly against closed-weights alternatives. The earlier leaderboard established the transparency and reproducibility principles that HELM Arabic Enterprise now applies to the more demanding territory of enterprise use.
[Written and edited with the assistance of AI]
Source: Arabic AI, Stanford CRFM
LINKS
HELM Arabic Enterprise Leaderboard (Stanford CRFM)
HELM ArabicEnterprise Scenarios Data (Github)
HELM Arabic Enterprise blogpost (Stanford CRFM)
Read more about Arabic benchmarks:
New community-driven Arabic TTS leaderboard (Middle East AI News)
Stanford collabs with Arabic AI for HELM Arabic (Middle East AI News)
HUMAIN reveals Arabic TTS benchmark (Middle East AI News)
TII releases new Arabic STEM AI benchmark (Middle East AI News)
Inception & MBZUAI share Arabic AI Leaderboards Space (Middle East AI News)